
Primerament buscaré seqüčncies homňlogues a la seqüčncia P11018 usant PSI-Blast sobre Swissprot amb dues iteracions (veure resultats).
A continuació, utilitzant la matriu creada amb PSI-Blast sobre Swissprot aplicaré PSI-Blast sobre PDB amb dues iteracions (veure resultats).
A continuació faré un alineament d'algunes de les proteďnes obtingudes amb PSI-Blast tant sobre Swissprot com sobre PDB mitjançant Clustalw (veure resultats). El motiu d'incloure seqüčncies obtingudes des de Swissprot és que, al formar part de la matriu emprada per cercar a PDB, poden contribuir a millorar l'alineament, especialment pel que fa referčncia a la localització dels gaps.
| PROTEĎNES SELECCIONADES PER L'ALINEAMENT | ||
|---|---|---|
| Referčncia | E-value | Font |
| P29139 | e-105 | Swissprot |
| P29140 | 3e-81 | Swissprot |
| 1scja | 4e-81 | PDB |
| 1aqn | 3e-77 | PDB |
| 1bh6a | 3e-77 | PDB |
| 1tece | 4e-66 | PDB |
Com es por observar he agafat seqüčncies amb e-values diferents així com amb variació entre elles per tal de fer un alineament significatiu per tal d'optimitzar la realització del model.
Una vegada executat l'alineament faré el model. Per fer-ho, primerament canviaré el format de l'alineament mitjançant el programa aconvertMod2.pl:
Per fer el model, totes les seqüčncies han de pertŕneyer a PDB (cal recordar que PDB és una based de dades d'estructura de proteďnes, perň Swissprot no), per tant eliminaré de l'alineament les seqüčncies pertanyents a Swissprot (veure resultats). També he eliminat la seqüčncia 1tece, ja que Modeller no s'executa si hi és present.
A continuació, modificaré l'arxiu p7.top (donat com a exemple) per adequar-lo a les seqüčncies i arxius del meu model (veure arxiu.top), i executaré Modeller:
Modeller genera dos models, que al llarg dels diferents anŕlisis anomenaré Model 1.1 i Model 1.2:
| Model 1.1 | Model 1.2 | |
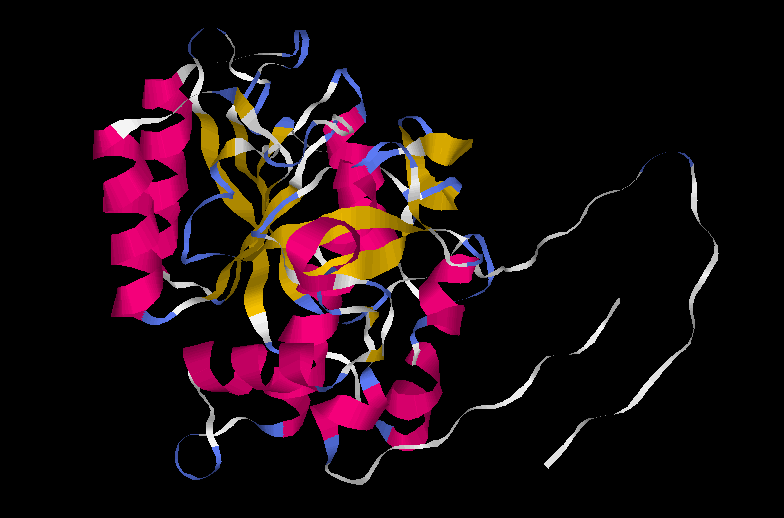 | 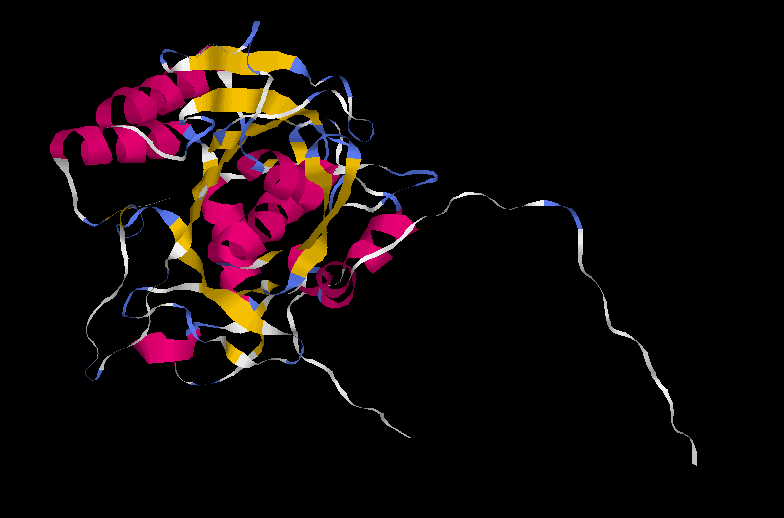
| |
| click to enlarge | click to enlarge | |
| click to see file | click to see file |