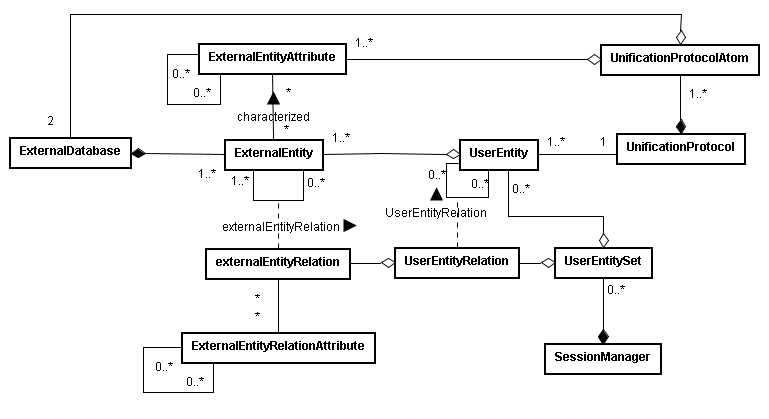
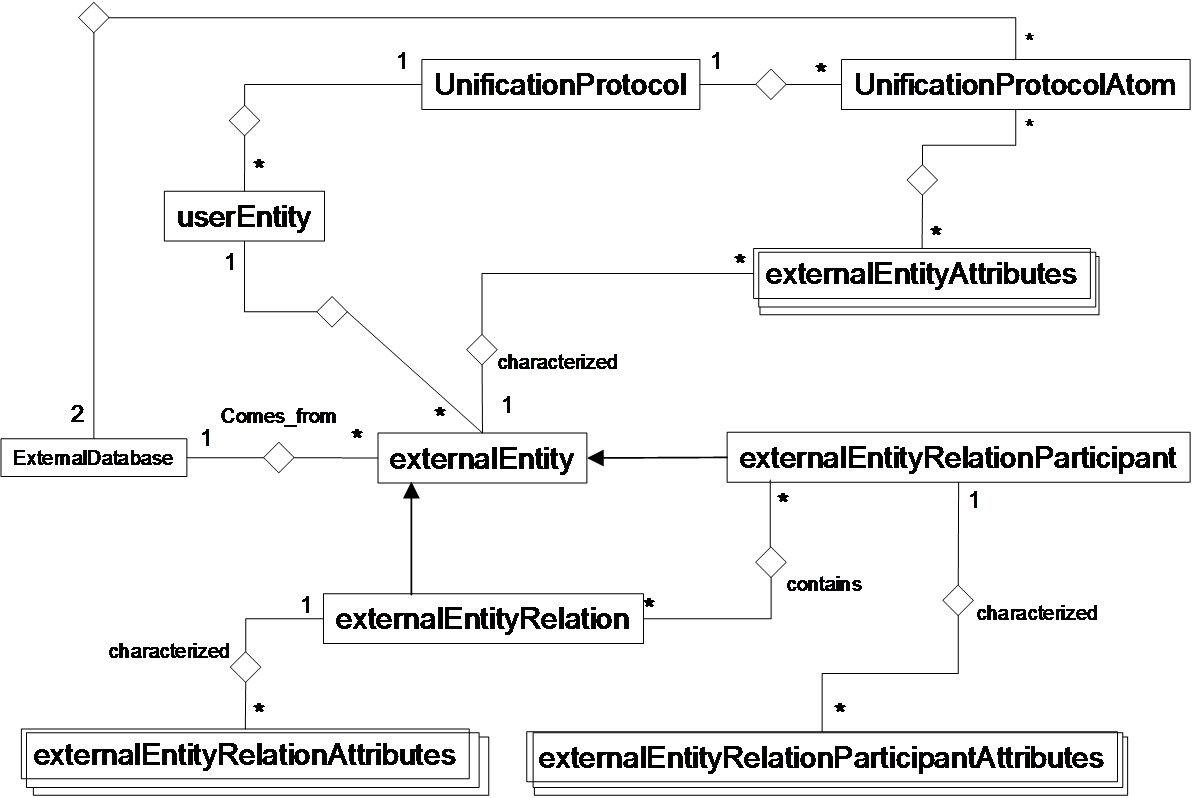
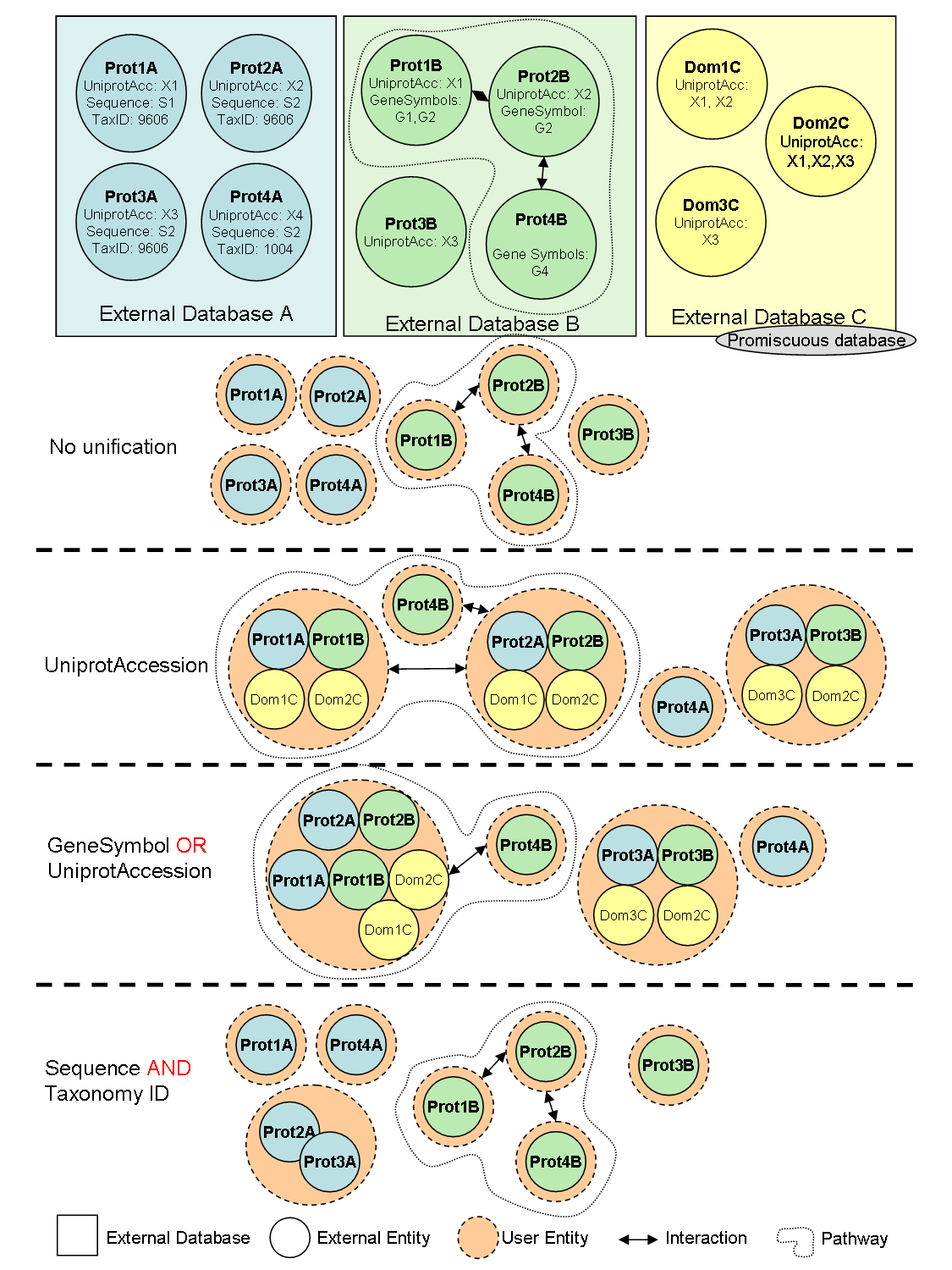
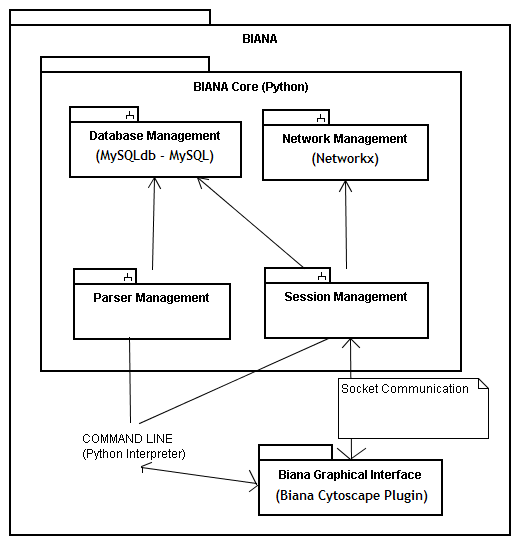
BIANA (Biologic Interactions and Network Analysis) is a biological database integration and network management framework written in Python. It uses a high level abstraction schema to define databases providing any kind of biological information (both individual entries and their relationships). Any data source that contains biologic or chemical data parsed by BIANA is defined as an external database. Similarly BIANA integration approach adopts the concept of external entity, corresponding to entries in external databases. For example, a uniprot entry (a protein), a GenBank entry (a gene), an IntAct interaction (an interaction), a KEGG pathway (a metabolical relation) or a PFAM alignment are all represented as external entities. In order to achieve data uniformity, in the cases where the data repository supplies relations, both participants and relation itself are considered as external entities, whereas the relation itself is annotated as external entity relation which is a subtype of external entity. External entity objects are characterized by several attributes, such as database identifiers, sequence, taxonomy, description or function. Each external entity relation object is further characterized by some attributes like detection method and reliability. Alternatively, the participants in external entity relations can have their particular attributes like role and cardinality. BIANA unifies external data inserted into its database using its parsers based on a specific protocol. This protocol, called unification protocol, consists of a set of rules that determine how data in various data sources are combined (crossed). Each rule is composed of attributes that have to be crossed and the external databases which are going to be used. The set of external entities that are decided to be "equivalent" with respect to a given unification protocol is called user entity. User entities inherit all the attributes of their included external entries. Thus, BIANA utilizes user entries specific to a certain unification protocol chosen by the user. User can either use provided built-in unification protocols or create his/her own unification protocols. As an example, a user may be interested in creating a unification protocol defined by crossing similar sequences and same taxonomy between two or more databases and crossing entities by uniprot accession code. The advantages of this integration approach are: 1) BIANA database only contains raw data (with exactly the same nomenclature and identifiers of the original data source), therefore does not entail any assumption on data integration allowing user to specify how the integration should be done; 2) User can use information from a single database or the combination of multiple databases, selecting which ones he wants to use at each moment; 3) User can know exactly how was the original data, and do a backtracking of his/her integration approach.
Requirements
WINDOWS
Cytoscape 2.6 (http://www.cytoscape.org/) (only required if BIANA is going to be used as a Cytoscape Plugin)
BIANA Cytoscape Plugin (copy this file into Cytoscape plugins path). You can also install the BIANA Cytoscape Plugin by using the Cytoscape Plugins Manager (Plugins -> Manage Plugins -> Change Download Site -> Edit sites -> Add http://sbi.imim.es/data/biana/Biana_cytoscape_plugin.xml) Version: 1.2.6, uploaded on Nov 3rd, 2009
Execute Cytoscape and run BIANA Cytoscape plugin (Plugins -> BIANA).
Click on Configuration button and select Preferences.
Check the Python Interpreter is correctly assigned: In Windows, select the file biana.bat (found in you BIANA installation path). In UNIX based systems, select your Python interpreter (usually found at /usr/bin/python).
Getting Started
Starting BIANA in Cytoscape
o
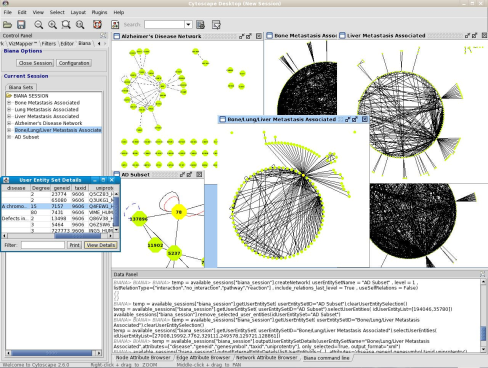
On the Cytoscape menus at the top, go to Plugins and then click on BIANA as demonstrated in Fig 1.1.
Figure 1.1: Starting BIANA from Cytoscape
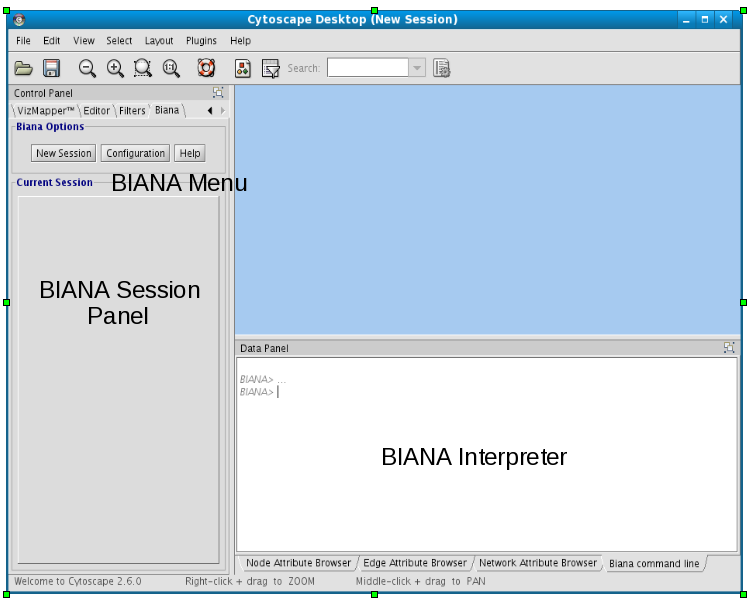
Once BIANA is started, you should view the following section in the Cytoscape window (Fig 1.2).
Inside left Cytoscape panel:
BIANA Menu:
Main BIANA menu buttons.
BIANA Session Panel:
When a working session is started, all working elements can be accessed in this panel.
Inside bottom Cytoscape panel:
BIANA Interpreter:
Python interpreter where you can execute manually all BIANA commands and see how the graphical interface generates them.
Figure 1.2: BIANA inside cytoscape
Using online BIANA Database hosted at SBI
The online BIANA database has the following connection parameters (it is case-sensitive!):
User: biana_user
Password: biana_password
Database server: sbi.imim.es
Database Name: online_bianaDB
The online BIANA database contains the following External Databases:
Uniprot-Swissprot database
Gene ontology (GO)
NCBI Taxonomy database
PSI-MI ontology
IntAct database
MINT database
Reactome
Tutorial databases (theoretical example)
SBI datasets:
Inferred Metabolic Network
Transcription Factor cooperation and Regulated genes
Protein-protein interaction network predicted from sequences/structure distant patterns
You can access our online BIANA database for testing purposes. It allows you to skip the installation step of installing a MySQL server and the initial steps of database creation and population. However, our online BIANA database has the following limitations:
It only has READ permissions.
New databases, parse new data or create unification protocols are not allowed. If user tries to execute some of these operations, an exception will occur.
It is a reduced database, which only contains necessary data to execute the tutorial exercises.
Creating your own BIANA Database
See tutorial & reference manual on the Documentation page.
Please use BIANA Bug Tracker to report any bugs you have found (the username is bianauser and the password is bianapassword). Please do provide basic information that would help us to identify the problem (Operating system details, BIANA version, Cytoscape version, program input and output that lead to the problem, and -optionally- your email).
Our Favorite Bug Reportes
We would like to acknowledge the following people who have helped us a lot in improving the correctness of BIANA:
Khademul Islam, GRIB - Biomedical Genomics Lab, Barcelona
BIANA provides some default database parsers for most common databases and formats. BIANA has been designed to be able to store any kind of biologic database, relying on the user how he wants to integrate data between databases by choosing which combinations of attributes must be shared. However, due to the large number of different databases, formats and versions, and that often different versions of the same database have different formats, not all databases with biologic data have a current working BIANA Parser. Despite existing interchange standard formats, databases often change their formats, so parsers are not guaranteed to work in all database versions. In order to solve this problem, we provide a set of default parsers, that will be updated in this list of available parsers.
If you find an existing parser is not working any more for a new database version, or you are interested in having a parser for another database not available here, you can ask for us to make it (it can take some time), or try yourself creating a new parser (see 'How to make a parser for my own database or data' section below). Alternatively, you can use BIANA Generic Parser which accepts data in a prespecified tab-separated format. Once you convert your data you can user the Generic Parser to parse your data. Please refer to BIANA Manual on using Generic Parser.
Available Parsers
Parsed Database Name (or format)
Parser file
Uniprot
uniprotParser.py
PSI-MI 2.5 format
psimi25Parser.py
Biopax Level 2 format
biopaxLevel2Parser.py
Non-redundant Blast NR database
nrParser.py
Cluster Of Orthologous Genes Database (COGs)
cogParser.py
GeneBank
ncbiGenPeptParser.py
Taxonomy
taxonomyParser.py
Protein-protein interactions Open Biomedical Ontologies (PSM-MI OBO)
All parsers written in BIANA inherits BianaParser class found in biana/BianaParser/bianaParser.py. To write your own parser you need to create a new Python class whose parent is BianaParser. Then all you need to define is the arguments your parser would require in the __init__ (class constructor) method and overwrite parse_database member method which is responsible from reading and inserting information from your data files.
Here is an example parser (MyDataParser.py) to insert data in user specified format into BIANA. Let's go over the code.
First we start with subclassing BianaParser:
from bianaParser import *
class MyDataParser(BianaParser):"""
MyData Parser Class
Parses data in the following format (meaining Uniprot_id1 interacts with Uniprot_id2 and some scores are associated with both the participants and the interaction):
Uniprot_id1 Description1 Participant_score1 Uniprot_id2 Description2 Participant_score2 Interaction_Affinity_score
"""
name = "mydata"
description = "This file implements a program that fills up tables in BIANA database from data in MyData format"
external_entity_definition = "An external entity represents a protein"
external_entity_relations = "An external relation represents an interaction with given affinity"
Above we introduce our parser and give name and description attributes, mandatory fields that are going to be used by BIANA to describe this parser. Then we create __init__ method where we call the constructor of the parent (BianaParser) with some additional descriptive arguments. You can add additional compulsory arguments to be requested from user by including "additional_compulsory_arguments" with a list of triplets (argument name, default value, description) (see list of command line arguments accepted by BianaParser by default).
Next, we are going to overwrite parse_database method (responsible from reading and inserting information from your data files) where we introduce some initial arrangements to let BIANA know about the characteristics of the data we are going to insert:
def parse_database(self):"""
Method that implements the specific operations of a MyData formatted file
"""# Add affinity score as a valid external entity relation since it is not recognized by BIANA
self.biana_access.add_valid_external_entity_attribute_type( name = "AffinityScore",
data_type = "double",
category = "eE numeric attribute")
# Add score as a valid external entity relation participant attribute since it is not recognized by BIANA
# (Do not confuse with external entity/relation score attribute, participants can have their attributes as well)
self.biana_access.add_valid_external_entity_relation_participant_attribute_type( name = "Score", data_type = "float unsigned" )
# Since we have added new attributes that are not in the default BIANA distribution, we execute the following command
self.biana_access.refresh_database_information()
There are various attributes and types in BIANA to annotate data entries coming from external databases (see attributes and types recognized by BIANA for details). In case we need to use attributes/types that are not by default recognized by BIANA we need to make them known to BIANA as it is done above with add_valid_external_entity_attribute_type and add_valid_external_entity_relation_participant_attribute_type functions (see defining new attributes and types for details).
# Open input file for reading
self.input_file_fd = open(self.input_file, 'r')
# Keep track of data entries in the file and ids assigned by BIANA for them in a dictionary
self.external_entity_ids_dict = {}
for line in self.input_file_fd:
(id1, desc1, score1, id2, desc2, score2, score_int) = line.strip().split()
Above we open a file for reading and start reading the file. This is followed by converting data read from the file into objects BIANA will understand and insert them into database:
# Create an external entity corresponding to Uniprot_id1 in database (if it is not already created)
if not self.external_entity_ids_dict.has_key(id1):
new_external_entity = ExternalEntity( source_database = self.database, type = "protein" )
# Annotate it as Uniprot_id1
new_external_entity.add_attribute( ExternalEntityAttribute( attribute_identifier= "Uniprot", value=id1, type="cross-reference") )
# Associate its description
new_external_entity.add_attribute( ExternalEntityAttribute( attribute_identifier= "Description", value=desc1) )
# Insert this external entity into database
self.external_entity_ids_dict[id1] = self.biana_access.insert_new_external_entity( externalEntity = new_external_entity )
# Create an external entity corresponding to Uniprot_id2 in database (if it is not already created)
if not self.external_entity_ids_dict.has_key(id2):
new_external_entity = ExternalEntity( source_database = self.database, type = "protein" )
# Annotate it as Uniprot_id2
new_external_entity.add_attribute( ExternalEntityAttribute( attribute_identifier= "Uniprot", value=id2, type="cross-reference") )
# Associate its description
new_external_entity.add_attribute( ExternalEntityAttribute( attribute_identifier= "Description", value=desc2) )
# Insert this external entity into database
self.external_entity_ids_dict[id2] = self.biana_access.insert_new_external_entity( externalEntity = new_external_entity )
Finally we insert information of the interaction as follows:
# Create an external entity relation corresponding to interaction between Uniprot_id1 and Uniprot_id2 in database
new_external_entity_relation = ExternalEntityRelation( source_database = self.database, relation_type = "interaction" )
# Associate Uniprot_id1 as the first participant in this interaction
new_external_entity_relation.add_participant( externalEntityID = self.external_entity_ids_dict[id1] )
# Associate Uniprot_id2 as the second participant in this interaction
new_external_entity_relation.add_participant( externalEntityID = self.external_entity_ids_dict[values[1]] )
# Associate score of first participant Uniprot_id1 with this interaction
new_external_entity_relation.add_participant_attributes( externalEntityID = self.external_entity_ids_dict[id1],
participantAttribute = ExternalEntityRelationParticipantAttribute( attribute_identifier = "Score", value = score1 ) )
# Associate score of second participant Uniprot_id2 with this interaction
new_external_entity_relation.add_participant_attributes( externalEntityID = self.external_entity_ids_dict[id2],
participantAttribute = ExternalEntityRelationParticipantAttribute( attribute_identifier = "Score", value = score2 ) )
# Associate the score of the interaction with this interaction
new_external_entity_relation.add_attribute( ExternalEntityRelationAttribute( attribute_identifier = "AffinityScore",
value = score_int ) )
# Insert this external entity realtion into database
self.biana_access.insert_new_external_entity( externalEntity = new_external_entity_relation )
As a good programming practice we do not forget to close the file we red as follows:
self.input_file_fd.close()
Command line arguments accepted by parsers
By default BIANA parsers require:
"input-identifier=": path or file name of input file(s) containing database data. Path names must end with /.
"biana-dbname=": name of database biana to be used
"biana-dbhost=": name of host where database biana to be used is going to be placed
"database-name=": internal identifier name to this database (it must be unique in the database)
"database-version=": version of the database to be inserted"
The following optional arguments are also recognized:
"biana-dbuser=": user name for the specified host
"biana-dbpass=": password for the specified user name and host
"optimize-for-parsing": set to disable indices (if there is any) and reduce parsing time. Useful when you want to insert a considerable amount of data to an existing BIANA database with indices created
Attributes and types recognized by BIANA and defining new ones
BIANA uses a set of attributes and types to define external entities coming from external biological databases (such as Uniprot Accession, STRING id, GO id, etc... as attributes and protein, DNA, interaction, complex, etc... as types). If you write a parser specialized for a particular data you have, you could either use existing attributes and types to annotate the entries in your data or create new ones if existing ones do not work for you.
Here we give a list of valid BIANA attributes:
In case, you need to annotate your data with some attribute or type that does not belong to the lists given above, you can use the following methods to introduce your attributes and types to BIANA.
To add an;
Have you done a new BIANA parser for your own data or for another database? Submit you own parser and share it with others!
Frequently Asked Questions
Installation
How do I check whether python package is installed properly?
Execute python interpreter and try to import the package as below. If you interpreter prompts "BIANA>" string, is installed properly.
\\$> python
>>> import biana
If not, revisit the installation instructions and make sure that python package is installed properly.
What to do if Cytoscape gives package import error while starting plugin?
Make sure that you configured PYTHONPATH environment variable to include directory where python package is installed.
Restart your computer (to make sure that Cytoscape sees the changes you made to PYTHONPATH).
What should I do if I get "can not connect to MySQL database" error?
Check that MySQL server is running properly and (re)start it if necessary.
Check that database host and user information you provide is correct.
If you are MySQL server in your local host try using "127.0.0.1" instead of "localhost" as host name.
Database population
Is it normal that populating a takes more time than expected?
population time will depend on multiple factors that can produce differences in parsing between different computers: parsed database, disk free space, disk access speed, network speed if MySQL server is in other computer... can have two distinct states: Running and parsing. When parsing, state is in "parsing" mode, and when starting a Session it changes automatically to "running" mode.
Why does not recognize, a new parser I have created?
Make sure you copied your new parser into _Installation_ path/bianaParser. Then, should recognize the parser and it will appear in the graphical interface as well. If you are not sure where was installed, execute python interpreter and try the following.
\\$> python
>>> import biana
>>> biana.__path__
Data Unification
What is the best unification protocol to use, do you have any suggested unification protocols?
Create & use a unification protocol that suits best to your needs (specific to your problem). You may want to check proposed unification protocols section to have some ideas.
BIANA Execution
Why does the message "Optimizing database..." appear during a long time, when I start a Session?
This message only appears the first time you start a Session in a after adding a new external database in it. This process creates all necessary indices in the database to increase performance while running, and it is done after populating database in order to increase parsing performance. Depending on the Database size, this process can take from few seconds to a couple of hours.
If it takes too long, check your disk space where Database is stored is not full!
I do not have any entries when I create a new user entity set, what could be the reason?
If you created a unification protocol using only promiscuous databases, it is normal that you do not have any user entities. Data coming from promiscuous databases added to (multiple) user entities that contain at least one entry coming from a non-promiscuous entry.
There may not be any entry associated with your query, try to refine the attributes and values you have used.
Is it normal that creating networks takes too much time?
Huge and very connected networks can take some time. Be patient. Be sure you are doing the network you want to the correct level. If you don't want interactions between elements at the last level, don't add them!
If you are using the graphical interface as a Cytoscape Plugin, it usually slows down the process significantly. Execute the same process by command line. A trick is to create the set with Cytoscape, start the network at level 0 without relations at the last level, then save the commands into a file, then edit manually the file to set the correct level and finally execute the script.
Database connection has been lost when using Cytoscape plugin. Should I restart the plugin?
MySQL server usually closes connection after some time the connection has not been used (this time will depend on your MySQL server configuration). It is not necessary to restart the plugin, right-click in the Biana Session and select the option "Reconnect database".
When I execute Cytoscape plugin, it is very slow or Cytoscape exits suddenly.
When executing as a Cytoscape plugin, it consumes more time and memory than executing it as a command line application. You have different options:
By default, cytoscape.sh uses a maximum memory limit of 512Mb. If the program exceeds it, it will automatically exit without saving anything. You can increase this memory limit by modifying the parameter -Xmx512M when executing cytoscape.
If you are creating a huge network and you are not interested in visualizing it but only in getting the data, use scripts: it will be faster and it will require less computer resources. You can use the following trick to create the script you are interested in:
Run Cytoscape plugin, create the network at level 0 and perform all the operations you are interested in.
In the Session Popup Menu (right-click on Session), select the option "Save commands history".
Modify the saved script by changing all the parameters you want and execute it from command line.
Citing
How should I cite BIANA in my manuscipt?
Javier Garcia-Garcia, Emre Guney, Ramon Aragues, Joan Planas-Iglesias and Baldo Oliva, BIANA: A Software Framework for Compiling Biological Interactions and analyzing networks, in preparation.
Please cite original data sources as well as BIANA in your manuscript
Javier Garcia-Garcia, Emre Guney and Joan Planas-Iglesias are grateful to the support from "Departament d'Educació i Universitats de la Generalitat de Catalunya i del Fons Social Europeu". Baldo Oliva also acknowledges support from BSC and Mare-Nostrum facilities. This work was supported by grants from Spanish Ministry of Science and Innovation (MICINN) BIO2008-0205, and with FEDER support, PSE-0100000-2007 and PSE-0100000-2009, and from EU grant Etox (IMI 115002).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
